LLM 学习笔记

一、核心思想与实现途径
(一)核心思想
尝试通过模拟人类大脑的工作流程来训练一个计算机模型。
人类大脑的工作流程:阅读时根据某个词的上下文来判断和理解这个词的意思,尽管每个词都会有不同的意思和语义,但一旦被放入一个句子中,几乎所有的词的意思和语义都会被固定下来。
(二)实现途径
理解语义
首先,模型将输入文本拆分为最小语义单位(token),并将每个 token 映射为高维空间中的一个向量。通过在海量语料上进行训练,模型调整其参数,为这些向量赋予丰富的语义。
例如,在句子 "The bank robber fled to the river bank." 中,bank 这个 token 的初始向量是由“河岸”与“银行”等所有语境下的用法共同决定的,使其在向量空间中处于 “river” 和 “money” 等相关概念构成的区域之间。
理解上下文
接着,为确定每个 token 在具体语境下的精确含义,模型采用自注意力机制。以上述 bank 为例,初始时两个 bank 向量完全相同。目标是通过数学变换,将与 robber 相邻的 bank 向量向“金融”语义区域移动,而将与 river 相邻的 bank 向量向“地理”语义区域移动。
实现方式如下:模型引入三个可训练的线性变换矩阵(),将每个 token 向量分别投影至查询(Query)、键(Key)、值(Value)三个子空间。
-
查询与匹配:第一个
bank的查询向量()会与句中所有 token 的键向量()进行点积运算,以计算相关性。由于robber提供了强烈的“金融”语境,训练好的模型会使得 与 的方向高度接近,其点积结果远大于 与 的点积。 -
计算权重:所有点积结果通过 Softmax 函数归一化,生成一组注意力权重。 对应的权重会最高。
-
更新向量:第一个
bank的新向量表示,是句中所有 token 的值向量()的加权平均。权重最高的 将最大程度地影响bank的新向量,在向量空间中将其“拉向”金融犯罪的语义区域。
整个过程对所有 token 并行计算,并通过多层堆叠不断精炼,最终让模型准确理解每个 token 在上下文中的精确含义。
二、Transformer 架构的思想突破
Transformer 的核心突破在于其处理信息的哲学:它相信全局关系优于线性时序,极简假设优于特定偏置,迭代精炼优于一步到位,责任解耦优于混为一谈。
(一)并行化与全局视野
Transformer 彻底颠覆了 RNN/LSTM 的线性时序处理方式。RNN 必须按顺序处理文本,不仅速度慢,且在长序列中会丢失早期信息。Transformer 则抛弃了时间的束缚,通过自注意力机制中的 矩阵运算,一次性地、并行地计算出序列中每个词与所有其他词的关系。这本质上是将语言从一维的时间序列,还原成了一个高维的关系网络,实现了全局视野,极大地提升了效率和性能。
(二)归纳偏置的极简主义
“归纳偏置”是模型设计中对数据规律的预设假定。CNN 假定“局部性”,RNN 假定“时序性”,而 Transformer 的自注意力机制只做了一个极简的假设:输入是一组元素的集合。它不预设任何元素间的关系(如相邻更重要),认为任何两个元素间都可能存在关键联系。
正因如此,注意力机制本身是“置换不变的”,必须额外引入位置编码(Positional Encoding)来告知模型元素的原始顺序。这种极简偏置赋予了 Transformer 无与伦比的通用性,使其能处理语言、图像等任何能表示为“向量集合”的数据。
(三)迭代式精炼
单个自注意力层能力有限,Transformer 的威力来自将多个结构相同的块(Block)深度堆叠起来,实现对信息由浅入深、迭代式的精炼过程。
- 多层堆叠:第一层可能解决词义模糊,第二层在此基础上理解句法,更高层则理解逻辑关系。每一层都在前一层的基础上对序列的表示进行更复杂的重写。
- 残差连接:这是实现深度堆叠的关键。它像一条“高速公路”,允许原始信息直达更高层,确保模型在深度加工时不会“遗忘”初始信息。
这种架构模拟了人类的深度思考过程:从识别词义、分析句法到联系背景知识,逐层深入。
(四)解耦的智慧
Transformer 将一个词的“语义内容”(what it is)和它的“序列位置”(where it is)两种信息解耦处理,再进行融合。词嵌入(Word Embedding)负责编码纯粹的语义,而位置编码(Positional Encoding)负责编码纯粹的顺序信息,最后通过向量相加将二者合一。这种清晰的责任分离,使核心的注意力机制能专注于寻找关系,而无需分心处理顺序问题,令整个架构更灵活、强大。
三、核心缺陷
(一)缺乏真实世界模型与推理能力
LLM 本质上是文本统计的大师,而非物理世界的理解者。它的知识基于对海量文本中语言模式的学习,是二手的、描述性的,缺乏基于物理或逻辑规律的内在模型。这导致它在复杂的逻辑推理、数学和物理问题上,常常会犯低级错误。
(二)自回归的“近视”与缺乏规划能力
LLM 以自回归的方式逐词生成内容,这是一种贪心算法,每一步只选择局部最优的下一个词,缺乏高层次的全局规划能力。因此,在生成长文本时,模型可能会前后矛盾、重复观点或忘记早期情节。
(三)暴力美学与学习效率低下
Transformer 的成功很大程度上是“大力出奇迹”,依赖于庞大的数据集和算力,学习效率与人类相比极为低下。这不仅导致训练成本高昂,易形成技术垄断,也带来了严重的环境问题。
(四)不可解释性与不可控性
数千亿参数的模型是一个巨大的 “黑箱”,我们无法精确解释其给出特定回答的原因。这带来了若干问题:
- 幻觉(Hallucinations):自信地捏造事实,因为它是在生成“最可能的文本序列”,而非查询“真实的知识库”。
- 偏见(Bias):完美地复现并放大训练数据中存在的社会偏见。
- 可控性差:难以通过“微创手术”的方式修正模型的某个错误认知,无法像修改代码一样去编辑它的“知识”。
四、注意力机制(Attention Mechanism)
注意力机制
单头注意力
多头注意力
(一)自注意力(Self-Attention)
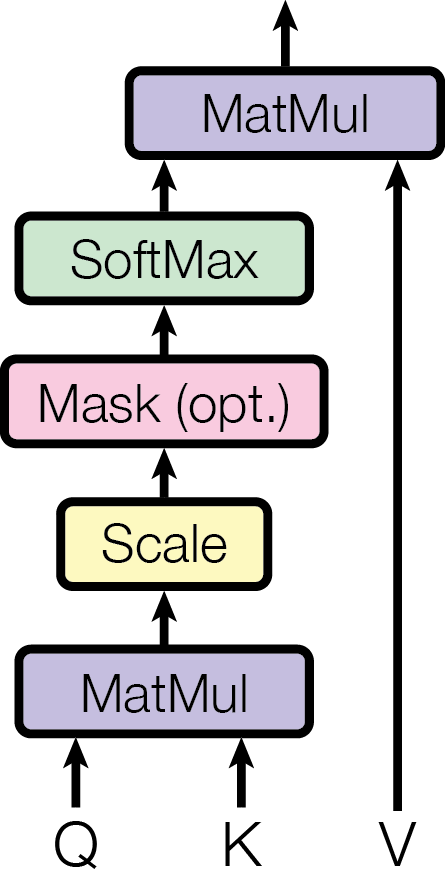
自注意力的核心思想是让模型在处理每个 token 时,都能动态地衡量序列中所有其他 token 对其自身的重要性。它通过以下步骤实现:
-
向量投影:每个输入的 token 向量会通过三个独立、可训练的线性变换矩阵()分别投影,生成三个向量:
- 查询向量 (Query, Q):代表当前 token 为了解自身发出的“查询”。
- 键向量 (Key, K):代表序列中每个 token 可供查询的“标签”或“索引”。
- 值向量 (Value, V):代表序列中每个 token 实际携带的“内容”或“信息”。
-
相关性计算:将当前 token 的 Q 向量与序列中所有 token 的 K 向量进行点积运算,得到它们之间的相关性分数。
-
权重归一化:将这些分数除以一个缩放因子(通常是 K 向量维度的平方根 ,以稳定梯度),然后通过 Softmax 函数转换为一组和为 1 的注意力权重。
-
加权求和:用这组权重去对序列中所有 token 的 V 向量进行加权求和,得到该 token 融合了全局上下文信息的新向量表示。
核心公式:
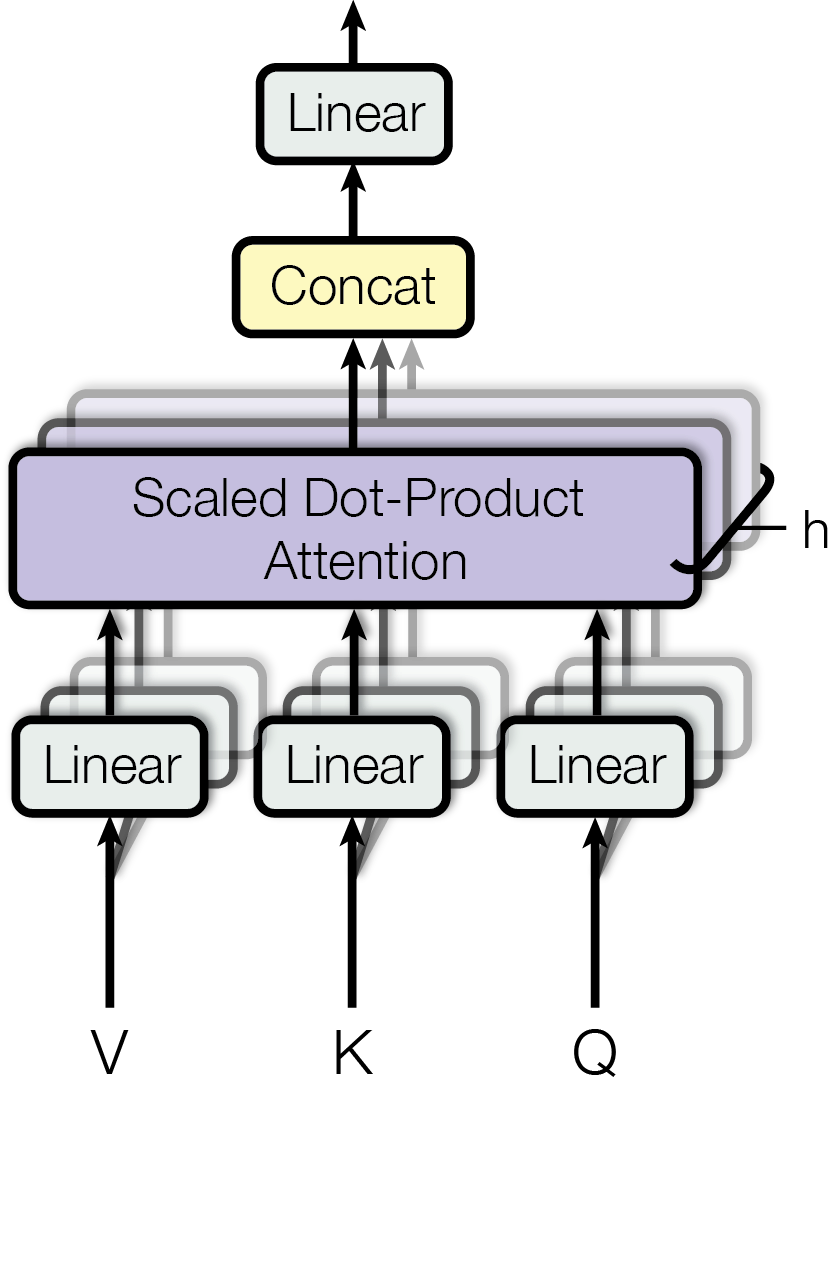
(二)多头注意力(Multi-Head Attention)
与其只进行一次高维度的自注意力计算,多头注意力机制将 Q, K, V 向量线性投影 h 次到更低的维度,并并行执行 h 次独立的注意力计算(称为“头”)。每个头可以学习关注输入序列中不同方面的信息(如句法、语义等)。最后,将这 h 个头的输出拼接起来,再通过一次线性变换()融合成最终的输出。这极大地增强了模型捕捉复杂关系的能力。
核心公式:
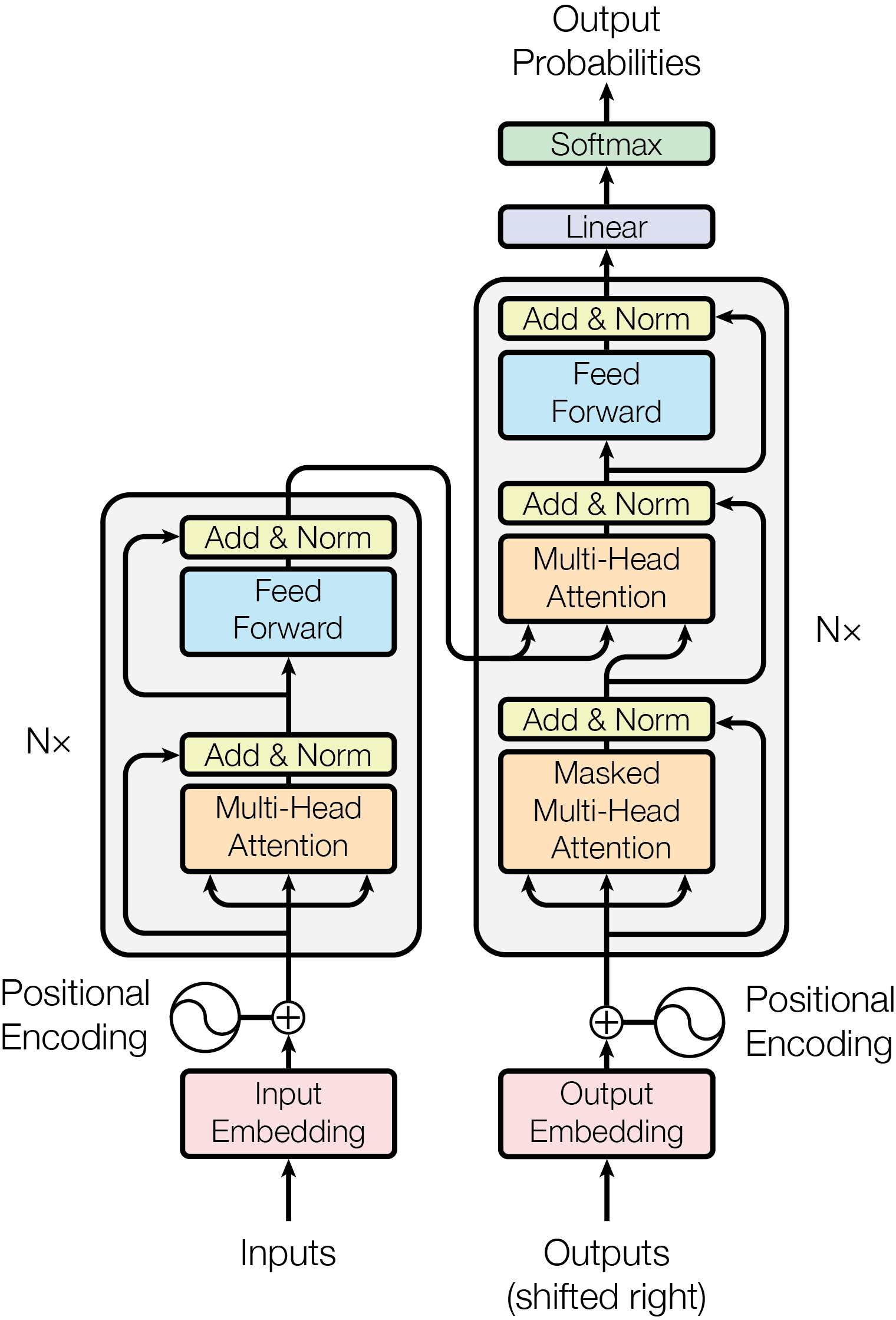
五、Transformer 架构
原始的 Transformer 采用编码器-解码器(Encoder-Decoder) 架构,主要用于翻译等序列到序列任务。许多现代 LLM(如 GPT 系列)则采用仅解码器(Decoder-only) 架构。
(一)核心组件
编码器块(Encoder Block)
由两个核心子层构成:一个多头自注意力层和一个前馈神经网络(Feed-Forward Network)。每个子层后都跟随一个残差连接与层归一化(Add & Norm)。编码器的作用是处理输入序列,生成包含了丰富上下文信息的向量表示(memory)。
解码器块(Decoder Block)
由三个核心子层构成:
- 掩码多头自注意力层:对解码器已生成的输出序列进行自注意力计算。其中的“掩码”机制确保在预测当前 token 时,模型无法“看到”未来的 token,这对于生成任务至关重要。
- 交叉注意力层(Cross-Attention):这是连接编码器与解码器的桥梁。该层的 Q 向量来自前一层的输出,而 K 和 V 向量则来自编码器的最终输出(memory)。它允许解码器在生成过程中“关注”输入序列的相关部分。
- 前馈神经网络层:与编码器中的功能相同。
同样,每个子层后都跟随一个残差连接与层归一化。
(二)工作流程
训练(以翻译任务为例)
- 编码:编码器接收源语言句子(如英语),经过多层处理后,输出一组包含其上下文信息的 K 和 V 向量(memory)。
- 解码:解码器接收目标语言句子(如法语,经过“右移”处理并加上起始符),通过掩码自注意力处理自身,然后通过交叉注意力查询编码器输出的 K 和 V,最后经前馈网络预测出下一个法语单词的概率分布。
- 优化:比较模型的预测与真实答案,计算损失,并通过反向传播更新模型中所有可训练的参数(如 等)。
推理(生成文本)
无论是翻译还是对话,模型的生成过程都是自回归(Auto-regressive) 的,即逐词生成:
- 模型接收一个初始序列(如翻译任务的
[BOS]符,或对话任务的用户提问)。 - 模型根据该序列预测下一个最可能的 token。
- 将新生成的 token 追加到序列末尾。
- 将更新后的序列作为新的输入,重复第 2、3 步。
- 这个循环持续进行,直到模型生成一个结束符
[EOS]或达到预设的最大长度。